Search in Common Headers or Body doesn't work
Reported by Alan Harper | November 28th, 2011 @ 04:27 PM
Hi
I am still evaluating MailMate, and I am concerned because not only are searches often slow (a reason I am abandoning Apple Mail), but they also fail to find emails. I was looking for a specific email in my inboxes, and a search was not finding it. After poking around, I found that (a) the search was failing, and (b) searches in other email client programs succeeded in finding it.
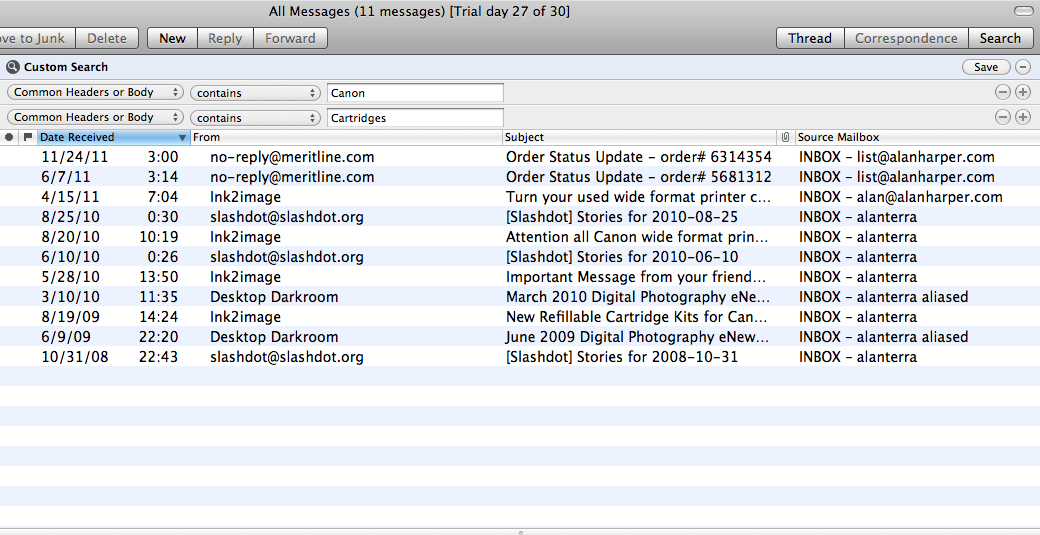
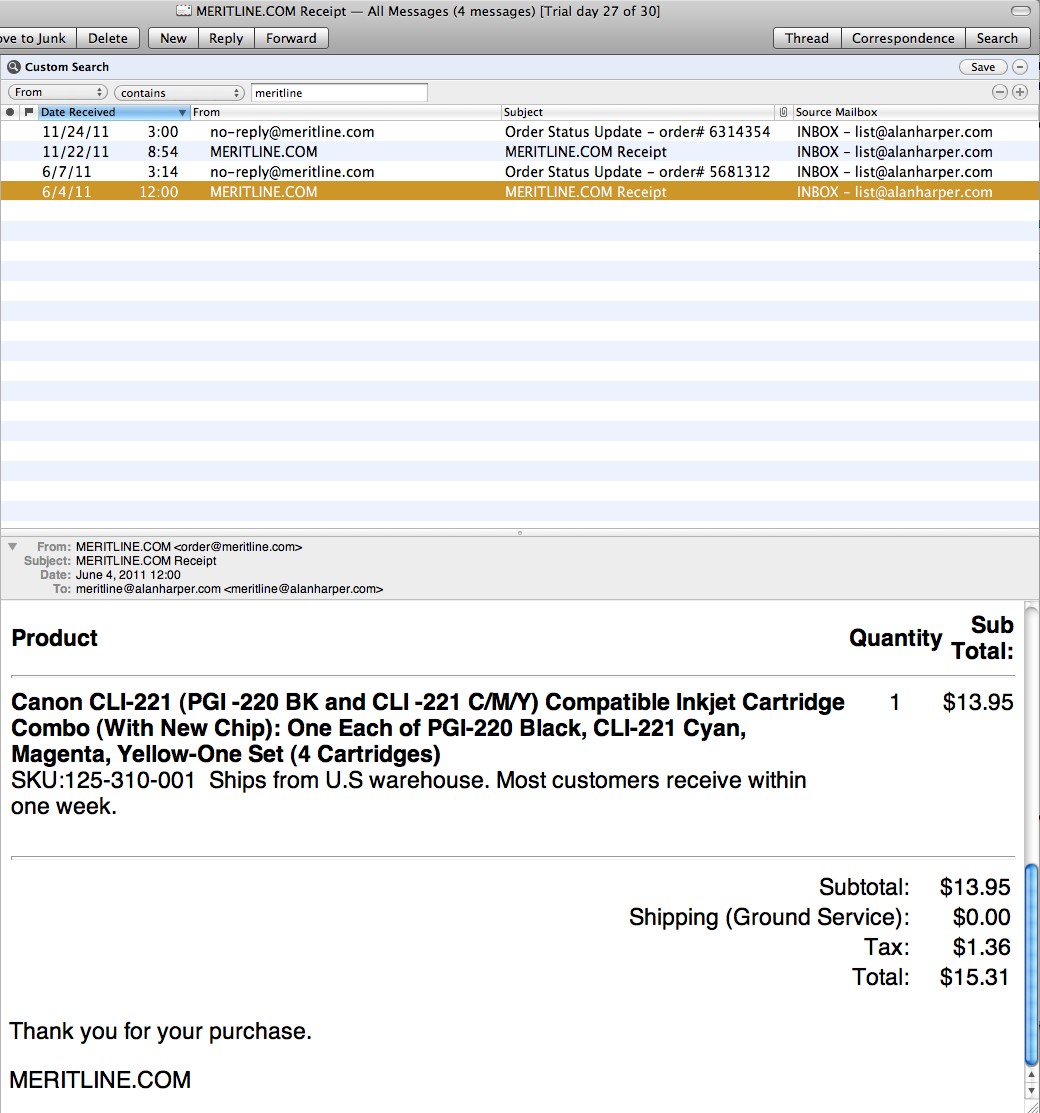
If you look at attachment 1, you will see that a search for "Canon" + "Cartridges" in my "All Messages" mailbox finds emails only on 24 Nov, 7 June, 15 April and earlier, while if you look at attachment 2, you will see an email sent on 4 June whose body clearly has the words Cartridges and Canon in it.
I rely on searching actually working in my email client. Any idea why it is failing here?
TIA
-
 screen-shot-2011-11-28-at-817.png
141.5 KB
screen-shot-2011-11-28-at-817.png
141.5 KB
-
 screen-shot-2011-11-28-at-818.png
173.9 KB
screen-shot-2011-11-28-at-818.png
173.9 KB
 screen-shot-2011-11-28-at-817.png
screen-shot-2011-11-28-at-817.png
 screen-shot-2011-11-28-at-818.png
screen-shot-2011-11-28-at-818.png
Comments and changes to this ticket
-

benny November 28th, 2011 @ 09:43 PM
- Assigned user set to “benny”
- State changed from “new” to “accepted”
If the problem is what I think it is then it is a known limitation. MailMate can currently only search so-called plain text body parts. Most of the time this is fine since any message with an HTML body part (the most often used alternative to plain text) should also contain a plain text body part with the plain text parts of the HTML body part. Unfortunately this is not always the case, in particular, when messages are generated by some web service. (You are actually the first to report this issue, so it is apparently not a frequent problem.)
You can verify this by looking at “View ▸ Message Body Parts” for the problematic message. Look for a plain text body part and if there is one, see if it contains the words you are looking for. Let me know if this does not explain what you are seeing.
Now, I do want to improve this, but this is for a different reason. Recently, Gmail allowed chat logs to be available via IMAP and these special messages only contain HTML body parts. And I would like to be able to search them. Consider that my personal motivation.
With respect to speed, text search is currently quite brute force. Some day it'll be improved, but I cannot make any promises with regard to time frame. If you mostly search relatively recent messages then you may find this tip useful.
I'll track any progress on HTML body part search in this ticket.
-
Alan Harper November 28th, 2011 @ 09:52 PM
The message looks like:
Delivered-To: xxx Received: by 10.147.136.13 with SMTP id o13cs68579yan; Sat, 4 Jun 2011 12:00:42 -0700 (PDT) Received: by 10.150.179.2 with SMTP id b2mr2880712ybf.410.1307214041816; Sat, 04 Jun 2011 12:00:41 -0700 (PDT) Return-Path: <order@meritline.com> Received: from APP2.meritline.com (app2.meritline.com [98.129.90.145]) by mx.google.com with ESMTP id q3si1387246ybe.67.2011.06.04.12.00.41; Sat, 04 Jun 2011 12:00:41 -0700 (PDT) Received-SPF: pass (google.com: domain of order@meritline.com designates 98.129.90.145 as permitted sender) client-ip=98.129.90.145; Authentication-Results: mx.google.com; spf=pass (google.com: domain of order@meritline.com designates 98.129.90.145 as permitted sender) smtp.mail=order@meritline.com Received: from 291875-app2 ([127.0.0.1]) by APP2.meritline.com with Microsoft SMTPSVC(7.0.6002.18264); Sat, 4 Jun 2011 12:00:41 -0700 MIME-Version: 1.0 From: MERITLINE.COM <order@meritline.com> To: "xxx" <xxx> Date: 4 Jun 2011 12:00:41 -0700 Subject: MERITLINE.COM Receipt Content-Type: text/html; charset=utf-8 Content-Transfer-Encoding: base64 Return-Path: order@meritline.com Message-ID: <291875-APP2ILBFZh4r000029a6@APP2.meritline.com> X-OriginalArrivalTime: 04 Jun 2011 19:00:41.0368 (UTC) FILETIME=[B30E3980:01CC22E9] PGh0bWw+DQogIDxoZWFkPg0KICAgIDxNRVRBIGh0dHAtZXF1aXY9IkNvbnRlbnQtVHlwZSIg Y29udGVudD0idGV4dC9odG1sOyBjaGFyc2V0PWlzby04ODU5LTEiPg0KICAgIDx0aXRsZT5N RVJJVExJTkUuQ09NIC0tLVJlY2VpcHQ8L3RpdGxlPg0KICA8L2hlYWQ+DQogIDxib2R5Pg0K ICAgIDxwIGFsaWduPSJjZW50ZXIiPjxiPjxmb250IHNpemU9IjMiPk1FUklUTElORS5DT03C oFJlY2VpcHQ8L2ZvbnQ+PGJyPjxmb250IHNpemU9IjEiPioqKiBQTEVBU0UgUFJJTlQgUkVD RUlQVCBPVVQgQU5EIFJFVEFJTiBJVCBGT1IgRlVUVVJFIFJFRkVSRU5DRSAqKio8L2ZvbnQ+ PC9iPjwvcD4NCiAgICA8dGFibGUgYm9yZGVyPSIwIiBjZWxsc3BhY2luZz0iMiIgY2VsbHBh ZGRpbmc9IjAiPg0KICAgICAgPHRyPg0KICAgICAgICA8dGQgYWxpZ249ImxlZnQiIHdpZHRo PSIyMCUiPg0KICAgICAgICAgIDxkaXYgY2xhc3M9InJlcG9ydCI+DQogICAgICAgICAgICA8 dGFibGUgY2VsbHBhZGRpbmc9IjAiIGNlbGxzcGFjaW5nPSIwIiB3aWR0aD0iMTAwJSI+DQog ICAgICAgICAgICAgIDx0cj4NCiAgICAgICAgICAgICAgICA8dGQgYWxpZ249ImxlZnQiIHZh bGlnbj0idG9wIj4NCiAgICAgICAgICAgICAgICAgIDx0YWJsZSBib3JkZXI9IjAiIGNlbGxz cGFjaW5nPSIyIiBjZWxscGFkZGluZz0iMCI+DQogICAgICAgICAgICAgICAgICAgIDx0cj4N CiAgICAgICAgICAgICAgICAgICAgICA8dGQgYWxpZ249ImxlZnQiIHdpZHRoPSIyMCUiPk9y ZGVyIE51bWJlcjo8L3RkPg0KICAgICAgICAgICAgICAgICAgICAgIDx0ZCBjb2xzcGFuPSIz IiB3aWR0aD0iODAlIiBhbGlnbj0ibGVmdCI+NTY4MTMxMjwvdGQ+DQogICAgICAgICAgICAg ...So I think that answers the question. Why they are sending it this way is unclear to me
-
benny November 28th, 2011 @ 10:03 PM
Yes, that is what I thought. In this case there is only one body part:
Content-Type: text/html; charset=utf-8Often such messages do contain a plain text body part which is then just a short note with an explanation or a link to a homepage with the same content as the HTML body part. Ironically, this makes it harder to know when it is necessary to parse HTML for text searching.
(I cut out your email address in the message in order to avoid it being picked up by any email address harvesters.)
-
Alan Harper November 28th, 2011 @ 10:09 PM
Thanks for removing the email. I would have thought that the harvesting came that company's error, not mine.
However, I get so much spam I just don't try to hide any more.
Cheers
-
benny May 25th, 2012 @ 02:18 PM
- State changed from “accepted” to “fixcommitted”
This is now implemented. It works like this:
- If only HTML is provided then it is converted and added to the database to be available for searching.
- If both plain text and HTML is available then the body parts are compared. If, heuristically, HTML has more content than plain text then HTML is handled like in 1.
(It can currently be a bit slow since external scripts are used for the conversion to plain text. Most noticeable if rebuilding the database.)
-
Please Sign in or create a free account to add a new ticket.
With your very own profile, you can contribute to projects, track your activity, watch tickets, receive and update tickets through your email and much more.
Create your profile
Help contribute to this project by taking a few moments to create your personal profile. Create your profile »
Mac OS X email client.
People watching this ticket
Attachments
-
 screen-shot-2011-11-28-at-8...
141.5 KB
screen-shot-2011-11-28-at-8...
141.5 KB
-
 screen-shot-2011-11-28-at-8...
173.9 KB
screen-shot-2011-11-28-at-8...
173.9 KB